OpenClaw 用着用着变水了?Fallback 背锅 + NVIDIA 免费白嫖 DeepSeek/Kimi/GLM 全攻略
1. 背景:龙虾哥突然变"水"了
最近两天,我在跟龙虾哥(我的 OpenClaw 助手)对需求的时候,感觉它的输出质量明显下滑--开始讲车轱辘话,回答变得客套,甚至有点"水"。
于是我打开 openclaw tui 直接测了一下,果然复现了——报了一个 401 错误。

就是这个 HTTP 401 authentication_error——Claude 接口认证失败,OpenClaw 触发了 Fallback(故障转移)机制,悄悄把模型切到了保底的 Gemini 上。
平心而论,Gemini 也很能打,但在处理中文互联网语境上还是差了点意思,导致输出显得有些"水土不服"。
2. 发现新大陆:薅老黄的羊毛
找到病因后,我想趁机试试国内的几个主流大模型(比如 DeepSeek、Kimi、GLM 等)。但痛点是:并没有购买相关厂商的套餐。
有没有什么方法能低成本试用这些国内主流大模型?
结果在找平替的时候发现了一片新大陆--NVIDIA(英伟达)!没想到浓眉大眼的老黄不仅卖显卡,还白送大模型 API。NVIDIA 的开发者平台不仅集成了包括 DeepSeek、Kimi、GLM、MiniMax 在内的一众国产顶流模型,还大方地给出了 每分钟 40 次请求(40 RPM) 的免费额度。
今天就把这套申请和配置的全过程分享给大家。
3. 实操:从注册到获取 Key
整个配置过程出乎意料的简单,只需要四步。
1. 访问地址:浏览器打开 https://build.nvidia.com
2. 注册/登录:点击右上角「Login」,输入邮箱,若账号不存在则进入注册流程,设置密码后 NVIDIA 会向邮箱发送验证码,输入后完成账号创建(全程无需绑卡)。
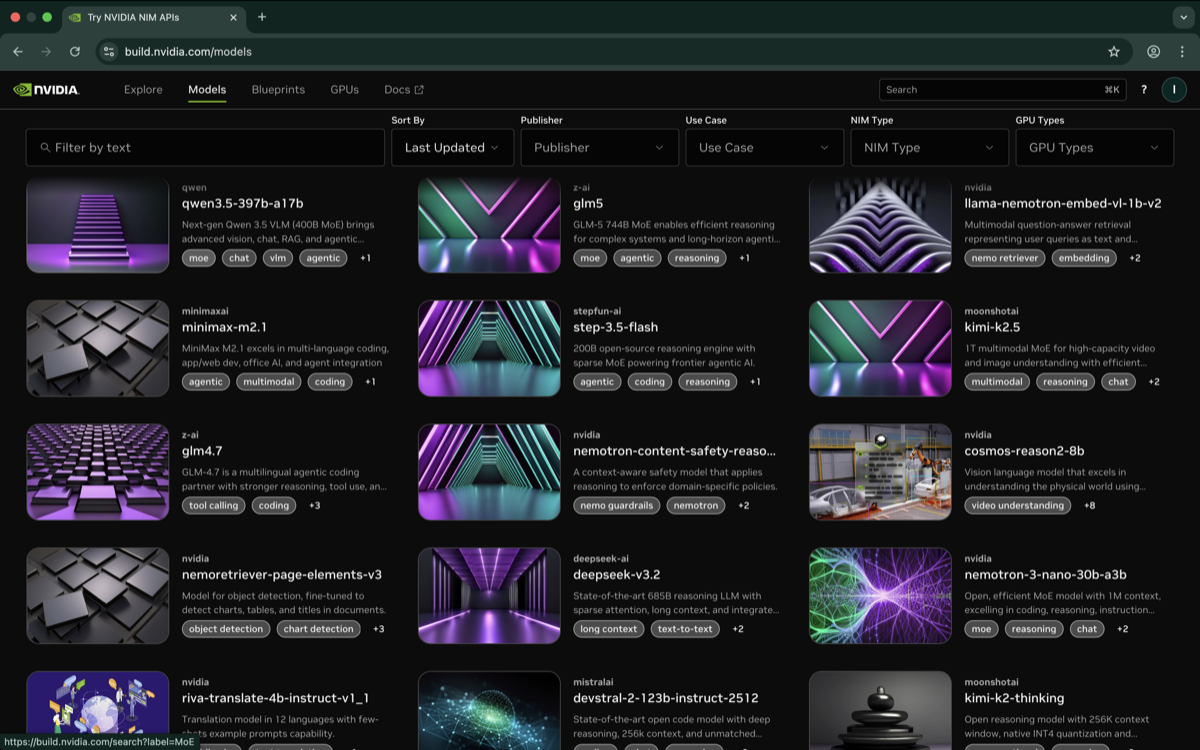
3. 手机号验证:在进行 API Key 申请前需要完成手机号验证:
- 点击主页右上角的「Verify」按钮
- 将国家代码从 +1 改为 +86(支持国内手机号)
- 输入手机号,点击「Send Code via SMS」发送验证码
- 输入收到的短信验证码,点击「Verify」完成验证
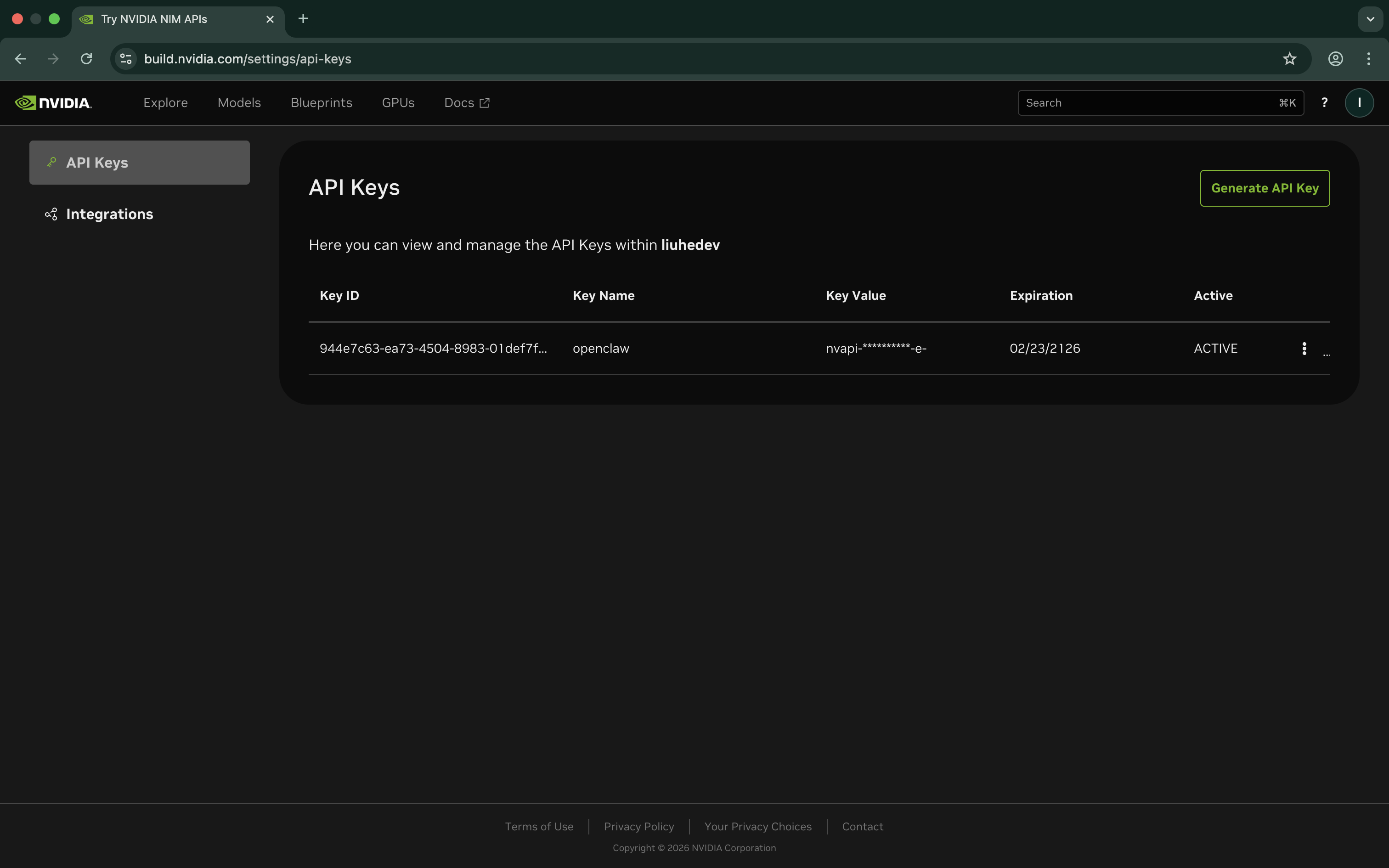
4. 生成 Key:
- 点击右上角头像,选择「API Keys」。
- 点击「Generate API Key」,输入 Key 名称,有效期选「Never Expire」(永不过期)。
- 点击「Generate Key」后会得到一串
nvapi-开头的密钥。 - ⚠️ 踩坑:Key 只会显示一次,记得马上复制保存!这一把钥匙,可以通用平台上所有的模型。
4. 核心干货:OpenClaw 配置全攻略
拿到密钥后,直接在底层框架(OpenClaw)里加几行配置就行。因为英伟达的接口完美兼容了 OpenAI 格式,所以只需要指定 baseURL 和对应的模型全名,就能无缝调用。
打开 ~/.openclaw/openclaw.json,在 models.providers 下新增 nvidia 节点:
{
"models": {
"mode": "merge",
"providers": {
"nvidia": {
"baseUrl": "https://integrate.api.nvidia.com/v1",
"apiKey": "nvapi-你的密钥",
"api": "openai-completions",
"models": [
{
"id": "deepseek-ai/deepseek-v3.2",
"name": "deepseek-v3.2",
"contextWindow": 128000,
"maxTokens": 8192
},
{
"id": "moonshotai/kimi-k2.5",
"name": "kimi-k2.5",
"contextWindow": 200000,
"maxTokens": 8192
},
{
"id": "z-ai/glm4.7",
"name": "glm4.7",
"contextWindow": 200000,
"maxTokens": 8192
},
{
"id": "minimaxai/minimax-m2.1",
"name": "minimax-m2.1",
"contextWindow": 200000,
"maxTokens": 8192
}
]
}
}
}
}
配置好 provider 之后,还需要告诉 OpenClaw 的 agent 系统该用哪些模型。在同一个 openclaw.json 里补充 agents 节点:
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"google/gemini-3.1-pro-preview",
"nvidia/deepseek-ai/deepseek-v3.2",
"nvidia/moonshotai/kimi-k2.5"
]
},
"subagents": {
"model": "google/gemini-3.1-pro-preview"
}
}
}
}
这样配置后:主 agent 优先用 Claude,挂了自动切 Gemini 3,再不行才用 NVIDIA 的免费模型兜底;子任务(subagents)默认跑 Gemini 3,省 Claude 额度。
几个注意点:
mode: merge表示与已有配置合并,不会覆盖其他 providerapi字段填openai-completions,NVIDIA 接口兼容 OpenAI 格式- 模型
id是 NVIDIA 平台上的完整路径,name是你在 OpenClaw 里调用时用的别名
配置保存后重启 gateway 生效:
openclaw gateway restart
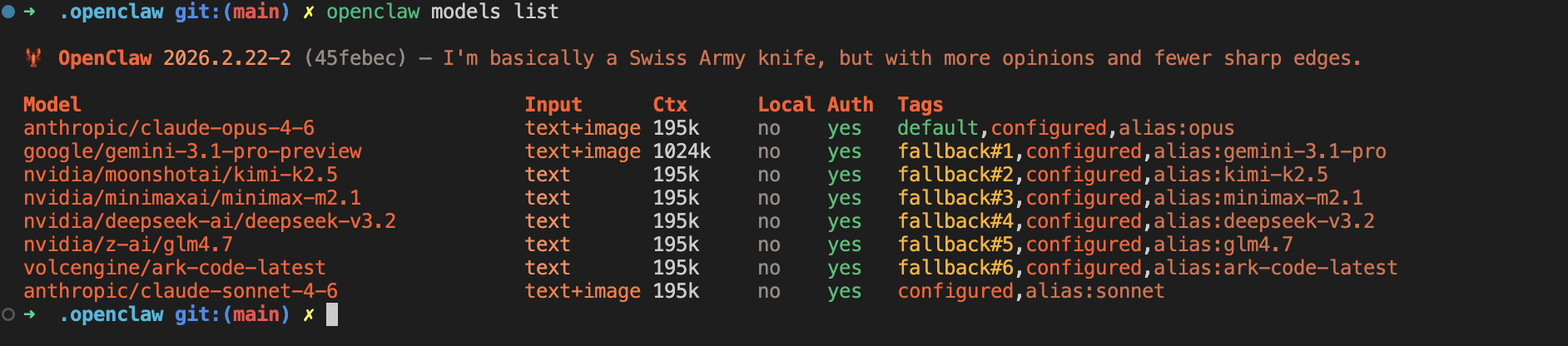
验证模型是否加载成功:
openclaw models list
5. 经验总结
1. Fallback 机制是把双刃剑:它能保证系统不宕机,但也容易掩盖底层模型悄悄降级带来的"智力下滑"。切换了模型要有感知,不然用户会以为是你变笨了。
2. 多关注硬件大厂的生态红利:NVIDIA 这种卖算力的巨头,为了推广自家的微服务架构,在 API 调用上通常非常慷慨。利用好大厂的生态红利,能极大降低我们探索 AI 的成本。
如果你也想体验下不同国产大模型的能力,又不想挨个注册充值,这里只提供一个试用思路:不妨拿老黄的这个平台作为零成本探索和测试的跳板!